



DATALAND는 ‘데이터의 시각화’와 ‘AI 예술에 전념하는 뮤지엄이자 웹3 플랫폼이다. DATALAND는 레픽 아나돌 스튜디오의 예술적 주도 하에 예술, 과학자, 기관 아카이브, 첨단 기술 등 다양한 분야의 선구자들을 한데 모으는 공간이 될 것이다.
DATALAND를 위해 레픽 아나돌 스튜디오는 세계 최초의 오픈 소스 생성형 AI 모델인 대규모 자연 모델(Large Nature Model)을 구축하고 있다. 이 모델은 자연 세계의 방대한 데이터를 기반으로 하며, 윤리적으로 수집된 데이터를 학습한 혁신적 시도이다. 스튜디오는 대규모 자연 모델의 알고리즘을 자연 고유한 지능에 기반해 훈련하는 독창적인 접근 방식을 개척하고 있다. 이는 인간 지성에 주로 의존하는 대부분의 대규모 언어 AI 모델과 차별화된 방식이다.
_데이터 수집
스미소니언 협회협회
수집된 개체 1억 4800만개
공개 표본기록 900만개
공개 이미지 630만장
런던 자연사 박물관
수집된 표본 8,000만개
공개 이미지 400만장
코넬 조류학 연구소
이미지 5,400만장
음성 녹음 200만개
비디오 425만 5천개
INATURALIST
이미지 1억 8,100만개
ENCYLOPEDIA OF LIFE
종 240만 4,791 종
텍스트로 된 형질/특성 1500만개
(특성/형질에 대한 추가 정보: HTTPS://EOL.ORG/TRAITBANK)
이 밖에 공개적으로 이용 가능한 이미지 소스 (총 2,440만 개 이미지)
프랑스 국립 자연사 박물관의 식물표본관 (MNHN – 파리) / 550만장 이미지
네덜란드 자연 생물다양성 센터 (NATURALIS) – 식물학 / 450만장 이미지
뉴욕 식물원 / 350만장 이미지
메이즈 식물원 허바리움 (벨기에) / 230만장 이미지
하버드 대학교 식물표본관: 전체 기록 / 140만장 이미지
리우데자네이루 식물원 연구소 (브라질) / 120만장 이미지
국제 생명바코드 프로젝트 (IBOL) / 100만장 이미지
호주 생물 지도 (ATLAS OF LIVING AUSTRALIA) / 500만장 이미지




LNM – PROCESS – 멀티모달 대규모 자연모델
자연의 상호 연결성과 이가 우리의 감각 경험에 미치는 영향을 기념하며, 레픽 아나돌 스튜디오는 자연 생태계에서 발견되는 복잡성을 반영하는 AI 모델을 개발하고 있다. 멀티모달 대규모 자연 모델(LNM)은 텍스트, 이미지, 오디오 및 비디오를 포함한 다양한 매체 전반에서 콘텐츠를 이해하고 생성할 수 있는 능력을 갖출 것이다.이 모델은 다양한 입력 데이터를 처리하고 통합하며, 이러한 여러가지 양식을 넘나드는 정보를 융합하여 새로운 콘텐츠를 생성할 것이다.
*멀티모달(multimodal): 여러 가지 다른 형태의 데이터나 입력 방식을 결합하여 처리하는 방식
LNM – AI 연구 과정
스튜디오의 작업은 업계 표준과 널리 받아들여진 확산 아키텍처에 기반을 두고 있다. 인공지능 확산 모델은 초반에 간단한 분포 위 노이즈를 추가하여 점점 더 많은 노이즈가 포함된 이미지를 생성한 후, 이 과정을 역으로 수행해가며 원본 이미지를 명확하게 복원한다. 이중 노이즈 처리 과정은 확산 모델의 핵심으로, 복잡한 이미지 분포를 효과적으로 생성하는 데 있어 차별화되는 요소이다.
LNM – 오디오 정보 검색 /머신 러닝 분류 – 조류
매콜리 도서관에서 수집된 2만 5천 개의 녹음 중 아마존 지역의 새 소리에 초점을 맞춰, 오디오 태깅을 위한 컨볼루션 신경망(CNN), 특히 MobileNetV3-Large를 활용한다. 이러한 방법을 통해 독특한 오디오 시그니처를 추출하고 분석할 수 있다. 결과 데이터는 3차원 공간으로 시각화되어 이러한 다양한 소리를 직관적으로 표현한다.
_참고
DDPM: JONATHAN HO, AJAY JAIN, AND PIETER ABBEEL.
DENOISING DIFFUSION PROBABILISTIC MODELS.
ARXIV PREPRINT ARXIV:2006.11239, 2020
*DDPM은 잡음을 제거하면서 점진적으로 데이터를 생성해내는 확률적 모델로, 주로 이미지 생성에 사용된다..
CLIP: GABRIEL ILHARCO, MITCHELL WORTSMAN, ROSS WIGHTMAN, CADE GORDON, NICHOLAS CARLINI, ROHAN TAORI, ACHAL DAVE, VAISHAAL SHANKAR, HONGSEOK NAMKOONG, JOHN MILLER, HANNANEH HAJISHIRZI, ALI FARHADI, AND LUDWIG SCHMIDT.
LEARNING TRANSFERABLE VISUAL MODELS FROM NATURAL LANGUAGE SUPERVISION.
*Clip은 텍스트와 이미지를 함께 학습해 언어와 시각적 표현을 연결시키는 AI 모델이다.
STABLE DIFFUSION: ROBIN ROMBACH, ANDREAS BLATTMANN, DOMINIK LORENZ, PATRICK ESSER, AND BJORN OMMER.
HIGH-RESOLUTION IMAGE SYNTHESIS WITH LATENT DIFFUSION MODELS.
*Stable Diffusion은 고해상도 이미지 생성을 위한 잠재적 확산 모델로, AI 기반 이미지 생성 기술이다.
UMAP: LELAND MCINNES, JOHN HEALY, AND JAMES MELVILLE
UMAP: UNIFORM MANIFOLD APPROXIMATION AND PROJECTION FOR DIMENSION REDUCTION.
*UMAP은 고차원 데이터를 저차원으로 줄여 시각화하거나 분석하는 데 사용되는 차원 축소 기법이다.
TRANSFORMER: ASHISH VASWANI, NOAM SHAZEER, NIKI PARMAR, JAKOB USZKOREIT, LLION JONES, AIDAN N. GOMEZ, LUKASZ KAISER, AND ILLIA POLOSUKHIN.
ATTENTION IS ALL YOU NEED.
*Transformer는 자연어 처리(NLP)에서 널리 사용되는 AI 모델로, 순차 데이터를 처리하는데 뛰어난 성능을 보인다.
DENOISING AUTOENCODER: PASCAL VINCENT, HUGO LAROCHELLE, YOSHUA BENGIO, AND PIERRE-ANTOINE MANZAGOL.
EXTRACTING AND COMPOSING ROBUST FEATURES WITH DENOISING AUTOENCODERS.
*Denoising Autoencoder는 잡음을 제거하며 데이터를 학습해 특징을 추출하는 신경망 모델이다.
WAVENET: AARON VAN DEN OORD, SANDER DIELEMAN, HEIGA ZEN, KAREN SIMONYAN, ORIOL VINYALS, ALEX GRAVES, NAL KALCHBRENNER, ANDREW SENIOR, AND KORAY KAVUKCUOGLU.
WAVENET: A GENERATIVE MODEL FOR RAW AUDIO.
*WaveNet은 사람의 목소리나 음악 같은 오디오 신호를 생성하는 신경망 모델이다.
GANSYNTH: JESSE ENGEL, KUMAR KRISHNA AGRAWAL, SHUO CHEN, ISHAAN GULRAJANI, CHRIS DONAHUE, AND ADAM ROBERTS.
GANSYNTH: ADVERSARIAL NEURAL AUDIO SYNTHESIS.
*GANsynth은 적대적 생성 신경망(GAN)을 사용하여 오디오 신호를 생성하는 모델이다.
LSTM: SEPP HOCHREITER AND JURGEN SCHMIDHUBER.
LONG SHORT-TERM MEMORY.
*LSTM은 시간에 따라 변화하는 데이터를 처리하는 순환 신경망의 일종으로, 장기 의존성을 학습하는 데 강점이 있습니다.
STYLEGAN: TERO KARRAS, SAMULI LAINE, AND TIMO AILA.
A STYLE-BASED GENERATOR ARCHITECTURE FOR GENERATIVE ADVERSARIAL NETWORKS.
*GAN의 변형으로, 다양한 스타일의 이미지를 생성하는 데 사용된다.
VARIATIONAL AUTO-ENCODER: DIEDERIK P. KINGMA AND MAX WELLING.
AUTO-ENCODING VARIATIONAL BAYES.
*VAE는 데이터의 잠재 공간을 학습해 새로운 데이터를 생성할 수 있는 신경망 모델이다.
ADAM: DIEDERIK P. KINGMA AND JIMMY LEI BA.
ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION.
*ADAM은 기계 학습에서 많이 사용하는 최적화 알고리즘이다.
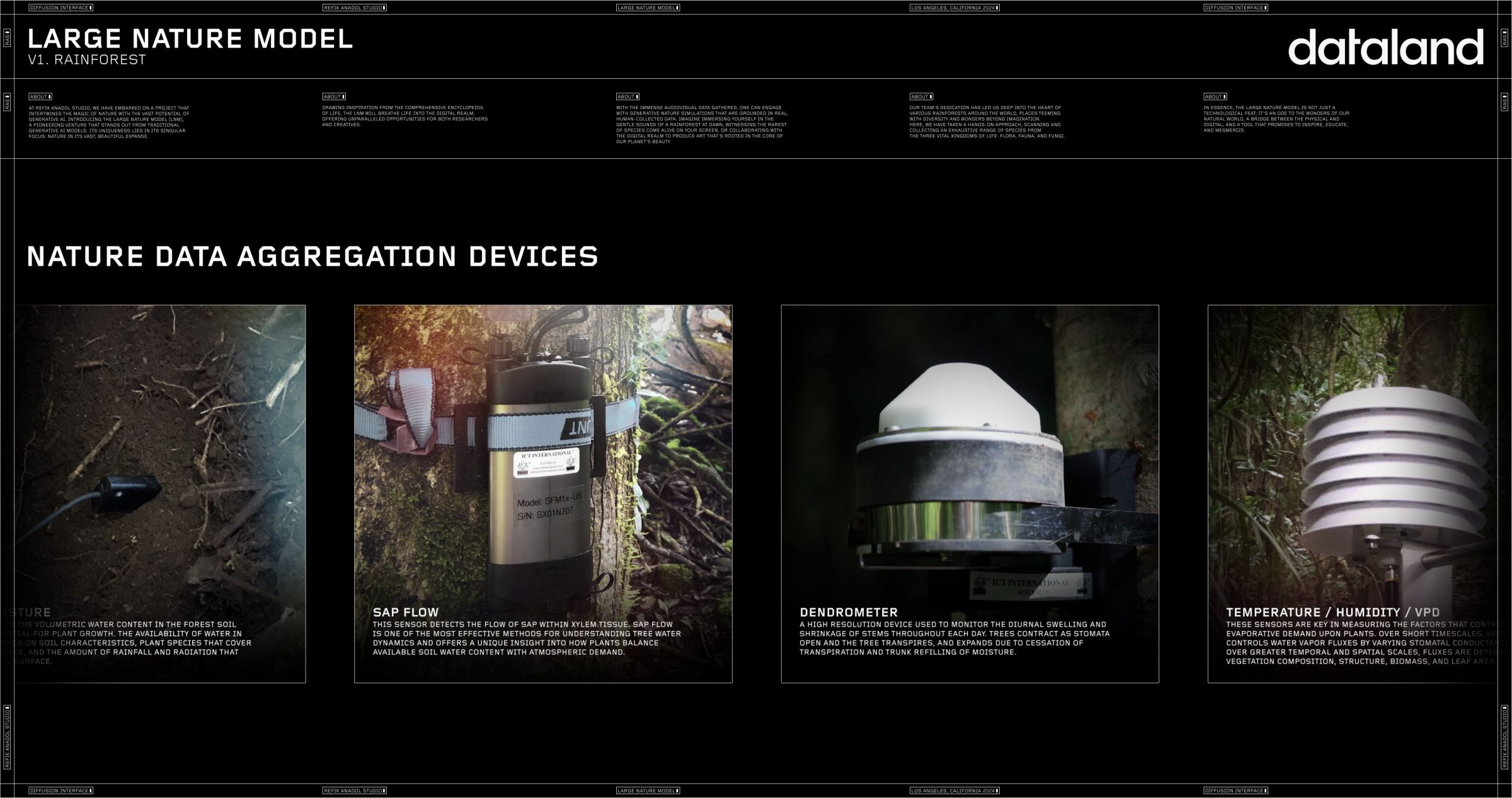
강우량 / 수관 통과량
이 센서는 엽층부를 통해 숲으로 들어가는 물의 지배적인 유입량을 측정한다. 수관 통과량은 전체적인 산림 물 균형에 영향을 미치고 토양 수분 패턴과 영양 주기를 결정한다.
토양 수분
이 수치는 식물 성장에 필수적인 산림 토양의 체적 수분 함량이다. 토양의 물 가용성은 토양 특성, 지표면을 덮고 있는 식물 종, 토양 표면에 도달하는 강우량과 방사선량에 따라 달라진다.
수액 흐름
이 센서는 목질부 조직 내에서 수액의 흐름을 감지한다. 수액 흐름은 나무 물 역학을 이해하는 가장 효과적인 방법 중 하나이며 식물이 사용 가능한 토양 수분 함량과 대기 수요의 균형을 맞추는 방법에 대한 독특한 통찰력을 제공한다.
측수기
하루 동안 줄기의 일일 팽창 및 수축을 모니터링하는 데 사용되는 고해상도 장치로 나무는 기공이 열리고 나무가 생기면서 증산 중단 및 수분 보충으로 확장한다.
온도/습도/증기압차
이 센서는 식물의 증발 수요를 제어하는 요인을 측정하는 데 중요하다. 짧은 시간 동안 식물은 기공 전도도를 변화시켜 수증기 흐름를 제어하지만 더 큰 시간적 및 공간적 규모에 따라 흐름은 식물 구성, 구조, 생물량 및 잎 면적에 따라 결정된다.
광합성유효방사
잎에 의해 차단되는 빛의 측정값으로, 흡수, 반사 또는 투과될 수 있다. 흡수율은 복사의 스펙트럼 함량과 잎의 흡수 스펙트럼에 따라 달라진다
적외선 방사계
적외선 방사계는 인간 눈의 감지 범위를 벗어난 복사 에너지를 측정한다. 모든 물체는 적외선 에너지를 방출하며 적외선 복사의 강도는 물체의 절대 온도에 비례한다.
자연 데이터 집계 장치들

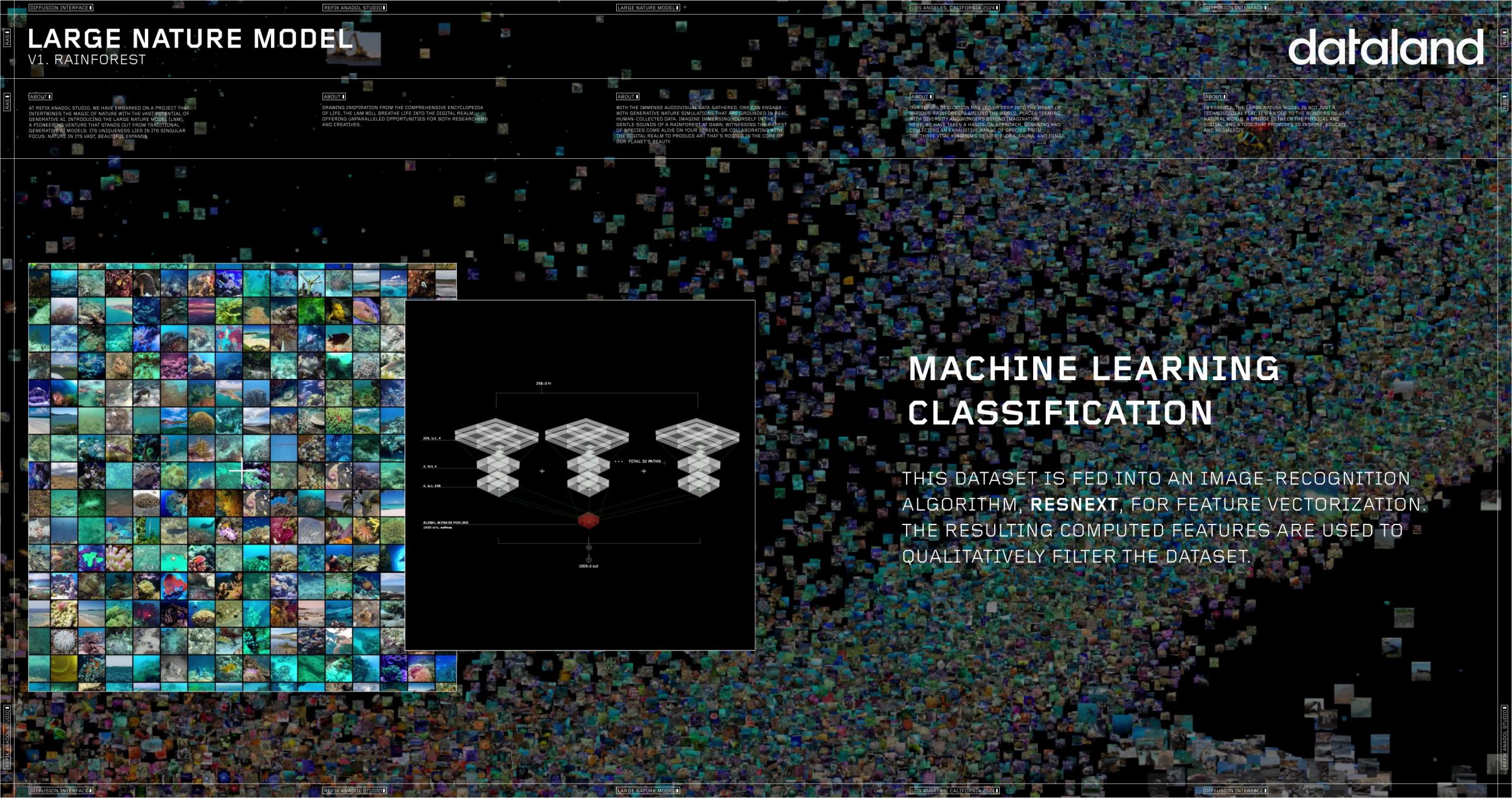


머신 러닝 분류
이 데이터세트는 이미지 인식 알고리즘인 ResNeXt에 입력되어 특징 벡터화가 이루어지고, 이의 결과로 생성된 특징들은 다시 데이터세트를 질적 필터링하는 데 사용된다.
CORAL DREAMS
정렬된 이미지 데이터세트는 산호 데이터 유니버스의 의미적 맥락을 더 잘 이해하기 위해 주제별로 분류된다. 이 확장되는 데이터 유니버스는 데이터를 합성의 형태로 보관하여, AI가 “꿈을 꾸는” 잠재력을 드러내는 숨겨진 우주가 된다. 이러한 다차원 공간에서의 꿈을 포착하기 위해, 레픽 아나돌 스튜디오는 NVIDIA의 StyleGAN2 ADA를 사용하여 AI 모델을 생성하고, 이 모델이 아카이브를 처리할 수 있도록 하였다. 모델은 정렬된 이미지의 하위 집합에서 훈련되었으며, 1,024차원에서 임베딩**을 생성했다.
*보간(Interpolation)은 AI가 기존의 데이터 포인트 사이에서 새로운 정보를 생성하거나 연속적인 패턴을 만들어내는 것을 의미한다.
**임베딩(embedding)은 기계 학습과 자연어 처리에서 자주 사용되는 개념으로, 데이터를 수치화하여 벡터 형태로 표현하는 방법을 의미한다. 이미지나 단어 등의 복잡한 데이터를 컴퓨터가 처리할 수 있는 고차원 공간의 벡터로 변환하는 것이다.
CORAL DREAMS 데이터
이 데이터세트에는 공개된 소셜 미디어 플랫폼에서 선별된 1,741,772장의 산호 이미지가 포함되어 있다.
CORAL 데이터 유니버스
큐레이팅된 산호 “데이터 유니버스”를 활용하는 CORAL DREAMS 프로젝트는 해양 환경에 자연스럽게 어우러져 귀중한 해양 생태계를 복원하는 데 도움이 될 수 있는, 3D 프린터로 출력 가능한 산호 “데이터 조각”을 제작하는 것을 목표로 한다.